Embedding the EL language
The \(\mathcal{EL}\) language is part of the Description Logics family. When trained with embed_dim=2, mOWL’s geometric EL models place classes as circles (ELEm), rectangles (ELBE), or rectangle pairs (Box²EL) and you can watch the geometry evolve during training — no dimensionality reduction needed:
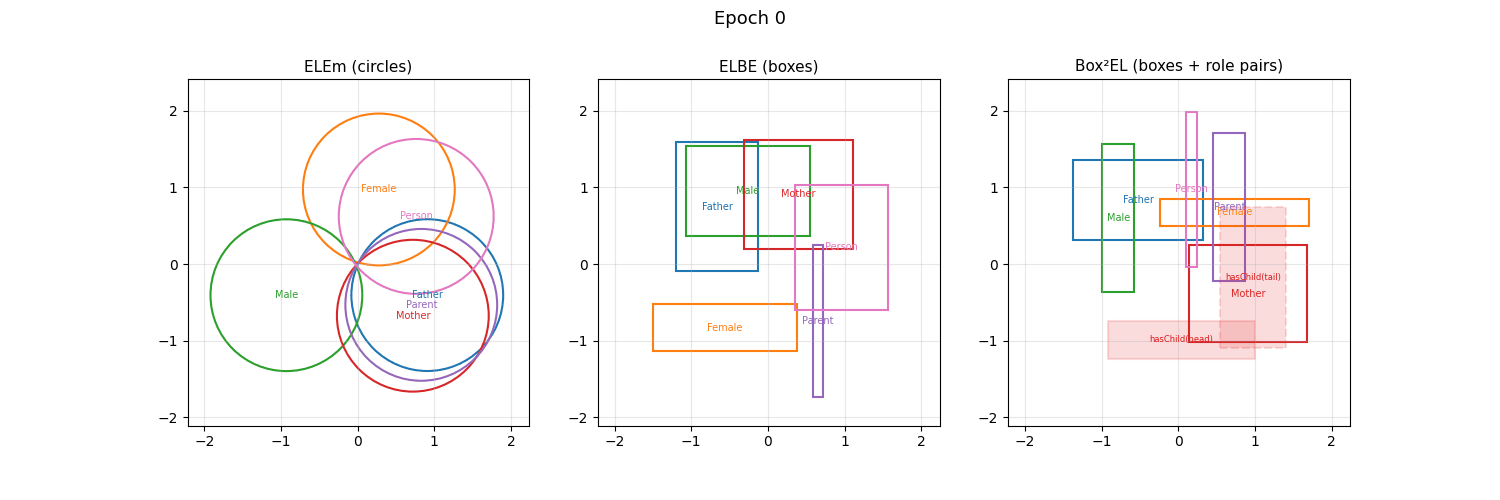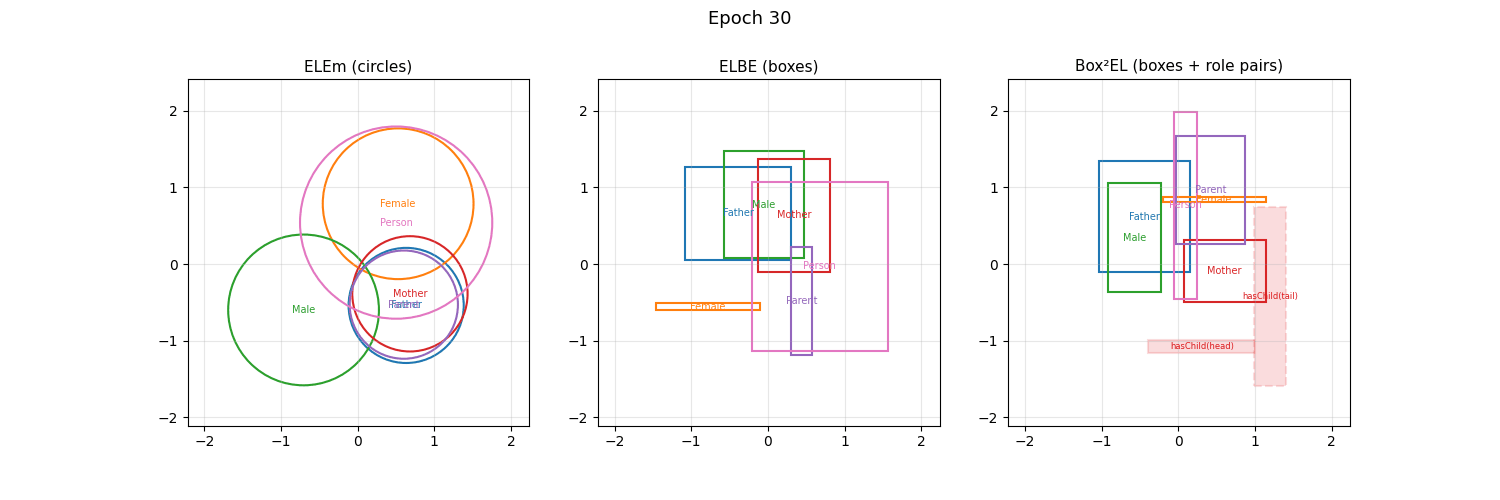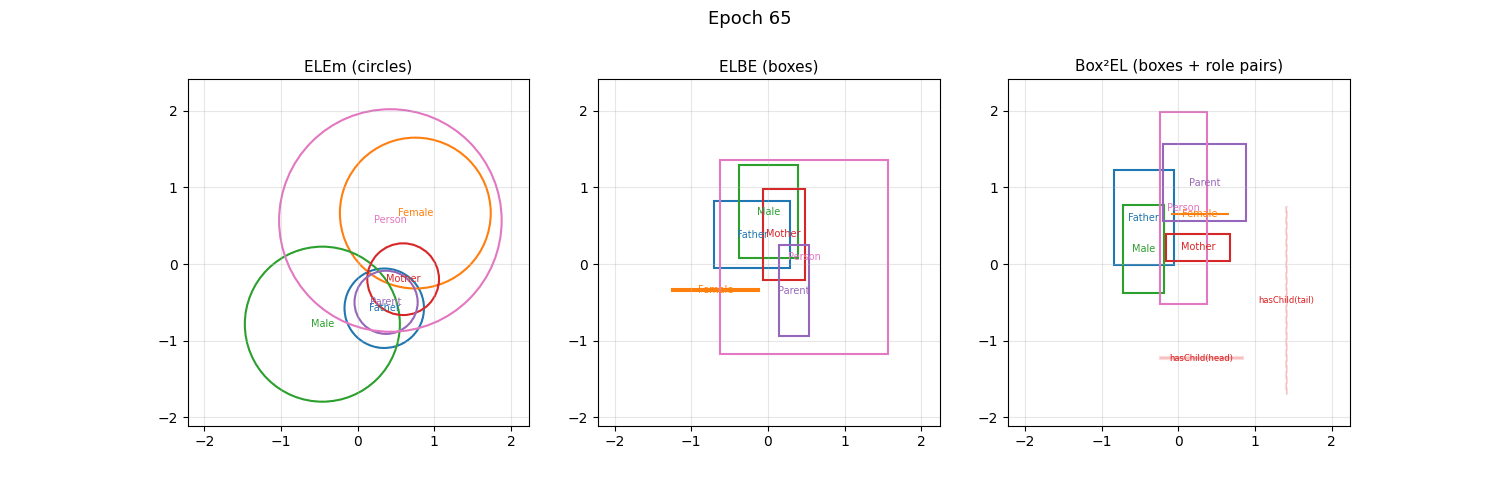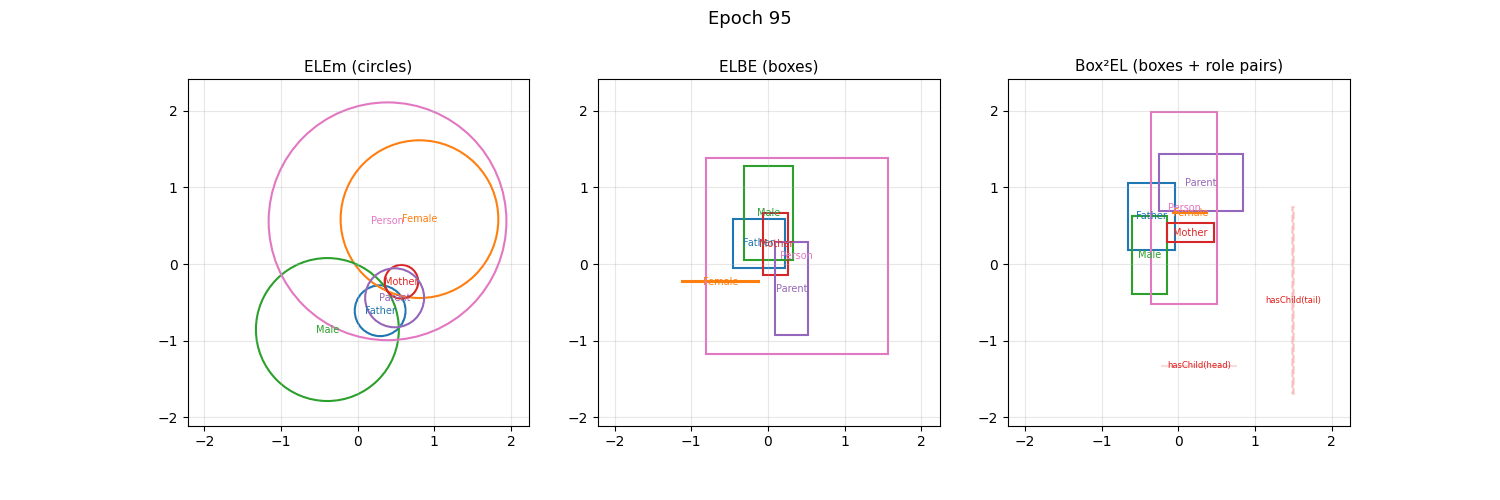
Concept descriptions in \(\mathcal{EL}\) can be expressed in the following normal forms:
Hint
GCI stands for General Concept Inclusion
The bottom concept can exist in the right side of GCIs 0,1,3 only, which can be considered as special cases and extend the normal forms to include the following:
mOWL provides different functionalities to generate models that aim to embed axioms in \(\mathcal{EL}\). Let’s start!
The ELDataset class
The ELDataset class is the first thing you should know about. mOWL first entry point are ontologies. However, not all of them are normalized in the \(\mathcal{EL}\) language. For that reason, we have to normalize the ontology. To do so, we rely on the Jcel library.
To create a \(\mathcal{EL}\) dataset use the following code:
from mowl.datasets.builtin import FamilyDataset
from mowl.datasets.el import ELDataset
ontology = FamilyDataset().ontology
el_dataset = ELDataset(
ontology,
class_index_dict = None,
object_property_index_dict = None,
extended = True)
As mentioned in the ELDataset API docs, the variable class_index_dict is a dictionary where keys are classes names and values are integer indices. The reason for this is that ELDataset is a collection of integer datasets and the class_index_dict dictionary keeps the mapping to the datasets. The same situation is true for object_property_index_dict, but it applies for ontology object properties.
The class dictionary can be predefined and input to the dataset. Otherwise it will be created from the input ontology.
The most important method of ELDataset is:
gci_datasets = el_dataset.get_gci_datasets()
That will return a collection of torch.utils.data.Dataset objects. If extended = False, then:
>> gci_datasets
{
'gci0': <mowl.datasets.el.el_dataset.GCI0Dataset at 0x7f977c9d4250>,
'gci1': <mowl.datasets.el.el_dataset.GCI1Dataset at 0x7f977c9d4220>,
'gci2': <mowl.datasets.el.el_dataset.GCI2Dataset at 0x7f977c9d42e0>,
'gci3': <mowl.datasets.el.el_dataset.GCI3Dataset at 0x7f977c9d4340>
}
which means that only 4 normal forms were obtained after the normalization process. On the other hand, if extended = True, then:
>> gci_datasets
{
'gci0': <mowl.datasets.el.el_dataset.GCI0Dataset at 0x7f67f3f4ff10>,
'gci1': <mowl.datasets.el.el_dataset.GCI1Dataset at 0x7f67f351c040>,
'gci2': <mowl.datasets.el.el_dataset.GCI2Dataset at 0x7f67f351c160>,
'gci3': <mowl.datasets.el.el_dataset.GCI3Dataset at 0x7f67f3f4feb0>,
'gci0_bot': <mowl.datasets.el.el_dataset.GCI0Dataset at 0x7f67f3f4ff40>,
'gci1_bot': <mowl.datasets.el.el_dataset.GCI1Dataset at 0x7f67f351c130>,
'gci3_bot': <mowl.datasets.el.el_dataset.GCI3Dataset at 0x7f67fc3b99d0>
}
in this case, normal forms 0, 1 and 3 have been split to consider apart the special cases where the \(\bot\) concept appears in the right side of each GCI.
The datasets generated can be used directly or through a torch.utils.data.DataLoader object. For example:
from torch.utils.data import DataLoader
dataloader_gci0 = DataLoader(gci_datasets["gci0"])
The ELModule class
Previously, we introduced the data-related aspect of this tutorial. Now, let’s see how to use the data to train a model.
In the mowl.nn module, we define the ELModule abstract class, which is a subclass of torch.nn.Module. To use this class, it is required to define loss functions for the GCIs of interest. For example:
from mowl.nn import ELModule
class MyELModule(ELModule):
# Declare which GCIs have a true negative loss implementation.
# Training will raise NotImplementedError for any other GCI that is
# configured for negative sampling.
neg_capable_gcis = frozenset({"gci2"})
def __init__(self):
super().__init__()
def gci0_loss(self, gci, neg = False):
"""
your code here
"""
# neg=True is NOT handled — gci0 is not in neg_capable_gcis
loss = 0
return loss
def gci1_loss(self, gci, neg = False):
loss = 1
return loss
def gci2_loss(self, gci, neg = False):
"""
your code here
"""
if neg:
# negative loss for GCI2
pass
loss = 2
return loss
def gci3_loss(self, gci, neg = False):
loss = 3
return loss
We have created an ELModule that computes losses for the GCI normal forms. Notice that negative sampling is opt-in per GCI: only GCIs listed in neg_capable_gcis will be used with negative samples during training. If negative sampling is requested for a GCI not in neg_capable_gcis, a NotImplementedError is raised at the start of training to prevent silent incorrect behaviour.
Note
Bot GCIs (gci0_bot, gci1_bot, gci3_bot) express subsumption by \(\bot\) and are never subject to negative sampling, since the concept of a “negative” disjointness axiom is not meaningful in this context.
Note
The ELModule also supports ABox axioms through class_assertion_loss for \(C(a)\) and object_property_assertion_loss for \(R(a, b)\).
Following these procedure is all what is needed. It is not necessary to define the forward function. However, let’s see how this works by looking at the implementation in the parent class:
import torch.nn as nn
class ELModule(nn.Module):
def __init__(self):
super().__init__()
"""
.
.
.
loss functions definitions here
.
.
.
"""
def get_loss_function(self, gci_name):
if gci_name == "gci2_bot":
raise ValueError("GCI2 does not allow bottom entity in the right side.")
return {
"gci0_bot": self.gci0_bot_loss,
"gci1_bot": self.gci1_bot_loss,
"gci3_bot": self.gci3_bot_loss,
"gci0" : self.gci0_loss,
"gci1" : self.gci1_loss,
"gci2" : self.gci2_loss,
"gci3" : self.gci3_loss,
"class_assertion": self.class_assertion_loss,
"object_property_assertion": self.object_property_assertion_loss
}[gci_name]
def forward(self, gci, gci_name, neg = False):
loss_fn = self.get_loss_function(gci_name)
loss = loss_fn(gci, neg = neg)
return loss
We can see that the already implemented forward function takes the data, the GCI name and the neg parameter. The idea here is that in the training loop we can get the losses for all the GCIs, and their potential negative versions and we can aggregate them appropriately. In the following section we will see an example of how to use use the ELModule and how it matches with the ELDataset class.
The ELEmbeddingModel class
At this point, it would be possible to just use the ELDataset and the ELModule together in a script to train a model.
Changed in version 2.0.0: Added the load_normalized parameter.
The EmbeddingELModel class accepts the following parameters:
dataset: mOWL dataset to use for training and evaluation.embed_dim: The embedding dimension.batch_size: The batch size to use for training.extended: IfTrue, the model works with 7 EL normal forms (including bottom concept forms). Defaults toTrue.load_normalized: IfTrue, the ontology is assumed to be already normalized and GCIs are extracted directly without running the normalizer. Defaults toFalse.device: The device to use for training. Defaults to"cpu".neg_sampling_gcis: List of GCI names for which negative sampling is applied during training. Defaults toNone, which automatically uses only the GCIs declared in the module’sneg_capable_gcis. Pass an explicit list to override — aNotImplementedErroris raised at the start of training if any requested GCI is not inneg_capable_gcis.
from mowl.datasets.builtin import PPIYeastSlimDataset
from mowl.models import ELEmbeddings
dataset = PPIYeastSlimDataset()
# Default: negative sampling is applied automatically for all GCIs declared in
# the module's neg_capable_gcis — no NotImplementedError will be raised.
model = ELEmbeddings(dataset, embed_dim=30)
# Explicit override: restrict to a specific subset.
# A NotImplementedError is raised at train() time if a requested GCI is not
# in the module's neg_capable_gcis.
model = ELEmbeddings(dataset, embed_dim=30, neg_sampling_gcis=["gci2"])
Alternatively, you can use ELDataset and ELModule directly without EmbeddingELModel:
from torch.utils.data import DataLoader
from mowl.datasets.el import ELDataset
from mowl.nn import ELModule
from mowl.datasets.builtin import PPIYeastSlimDataset
dataset = PPIYeastSlimDataset()
class_index_dict = {v:k for k,v in enumerate(dataset.classes.as_str)}
object_property_index_dict = {v:k for k,v in enumerate(dataset.object_properties.as_str)}
training_datasets = ELDataset(dataset.ontology, class_index_dict = class_index_dict, object_property_index_dict = object_property_index_dict, extended = False)
validation_datasets = ELDataset(dataset.validation, class_index_dict = class_index_dict, object_property_index_dict = object_property_index_dict, extended = False)
testing_datasets = ELDataset(dataset.testing, class_index_dict = class_index_dict, object_property_index_dict = object_property_index_dict, extended = False)
"""
Furthermore if we need DataLoaders (which might not be always the case)
"""
training_dataloaders = {k: DataLoader(v, batch_size = 64) for k,v in training_datasets.get_gci_datasets().items()}
#validation_dataloaders = ..
#testing_dataloaders = ...
model = MyELModule() #Let's reuse the module of the example before.
for epoch in range(10):
for gci_name, gci_dataloader in training_dataloaders.items():
for i, batch in enumerate(gci_dataloader):
loss = model(batch, gci_name)
# .
# .
# .
#More logic for training
# .
# .
# .
continue
In the previous script, there are some lines of code dedicated to preprocessing the data. That functionality is what is encoded in the ELEmbeddingModel such that if we use it, we can bypass all the data preprocessing and start directly in the training, validation and testing loops.
To see actual examples of EL models, let’s go to EL Embeddings and ELBoxEmbeddings.
Just use a mOWL model
We have seen that constructing a \(\mathcal{EL}\) model has many steps. However, the main difference between them, is the definition of loss functions and the training loop. Therefore, using the ELEmbeddingModel can be useful by just defining the training loop.
mOWL ships several ready-to-use \(\mathcal{EL}\) models that share this interface, so they can be swapped in without changing the surrounding code:
ELEmbeddings— classes as balls [kulmanov2019]ELBE— classes as axis-aligned boxes [peng2020]BoxSquaredEL— boxes with bumps for relations (Box²EL) [jackermeier2023]BoxEL— box embeddings for EL++ knowledge bases [xiong2022]
Here is an example of using ELEmbeddings for protein-protein interaction prediction:
from mowl.datasets.builtin import PPIYeastSlimDataset
from mowl.models import ELEmbeddings
from mowl.evaluation import PPIEvaluator
dataset = PPIYeastSlimDataset()
model = ELEmbeddings(dataset, embed_dim=30)
model.eval_gci_name = "gci2"
model.set_evaluator(PPIEvaluator)
model.train(epochs=1, validate_every=1)
After training, you can evaluate the model on the testing set:
model.evaluate(dataset.testing, filter_ontologies=[dataset.ontology])
print(model.metrics)
The metrics dictionary contains ranking-based metrics such as mean rank (mr), filtered mean rank (f_mr), and AUC (auc).
You can also access the learned embeddings:
class_embeddings = model.class_embeddings
object_property_embeddings = model.object_property_embeddings